

말랑말랑제리스타일
딥러닝에서 과적합의 의미와 간단한 ANN 모델 성능 평가 방법 본문
딥러닝에서 모델 생성을 완료했다면 어느 정도 정확도를 내는지 성능을 평가해야 되겠죠.
총 4가지 단계를 통해서 딥러닝 ANN 모델의 성능을 평가해 봤습니다.
여기서 과적합을 판단하는 방법도 알 수 있었는데 두 번째 단락에서 과적합의 의미를 설명드리겠습니다.
ANN 모델의 학습 결과 출력
이미 model.fit을 통해 결과를 확인했겠지만 이 결과를 epoch(반복 횟수) 별로 히스토리에 저장해 둘 수 있습니다.
history = model.fit(train_x, train_y, epochs=50, batch_size=50, validation_data=(valid_x,valid_y))이렇게 model.fit의 결과를 변수에 받아볼 수 있는데요.
저는 50회 epoch를 주고 history라는 변수에 저장했습니다.
history.history이후 이런 코드를 통해서 history를 출력해 볼 수 있는데요.
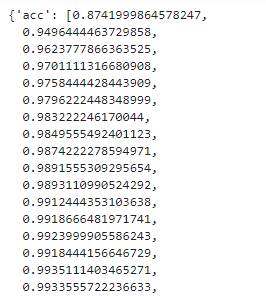
이렇듯 훈련 데이터에 대한 정확도가 올라가는 것이 출력이 되죠.
딥러닝에서 과적합이란?
여기서 과적합이 일어나는 부분이 있었습니다.
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(loss, c = 'r')
plt.plot(val_loss, c = 'g')
plt.show()이렇게 pyplot을 이용해서 훈련 데이터의 loss(손실)과 validation 데이터의 loss(손실)을 그래프로 나타내봤는데요.
참고로 소스를 못 읽으시는 분들을 위해 설명하면 빨간색이 훈련 데이터 손실, 녹색이 validation 데이터의 손실입니다.
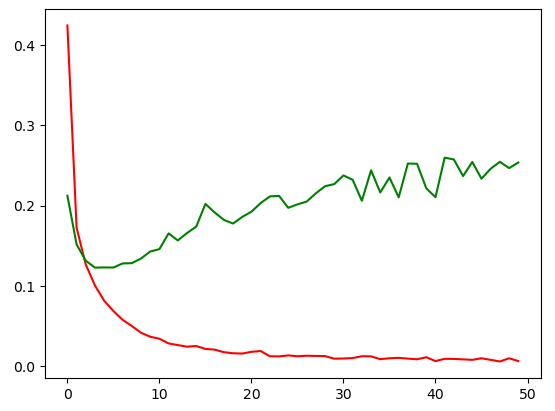
결과는 이렇게 출력이 됩니다.
훈련 데이터의 정확도가 줄어들고 있지만 사실상 크게 의미가 없고 Validation 데이터의 loss가 칠랑팔랑 하면서 증가하고 있습니다.
즉, 급격히 떨어진 이후 증가하는 시점부터는 과적합이라고 부르는 거죠.
하단의 0~50은 epoch 즉, 같은 데이터로 훈련한 횟수인데요.
약 4회 이상 훈련하면서부터는 정확도가 오히려 떨어지고 있다고 볼 수 있죠.
이렇게 훈련을 많이 했지만 오히려 정확도가 떨어지는 상태를 딥러닝에서 과적합 상태라고 부릅니다.
테스트 데이터로 실제 결과 예측
다음으로 아예 생짜 훈련할 때 사용하지 않은 테스트 데이터를 넣어서 결과를 예측해 봤습니다.
model.evaluate(test_x, test_y)약 97퍼센트의 정확도를 내는데요.
어디서 틀렸는지 확인해 봤습니다.
from sklearn.metrics import confusion_matrix
import numpy as np
pred = model.predict(test_x)
confusion_matrix(np.argmax(test_y, axis = 1), np.argmax(pred, axis = 1))사이킷 런의 confusion matrix와 numpy를 이용해서 만들어봤고 예측(predict)의 매개변수로는 답은 넣지 않고 테스트 데이터만 넣어줍니다.
이후 confusion matrix를 이용해서 일치하는 것과 일치하지 않는 것의 건수를 찾아내는 거죠.

일단 좌측 세로 데이터는 실제 레이블로 기댓값인데요. 위에 줄부터 0~9까지죠.
가로 데이터는 ANN 모델이 예측한 값으로 0~9까지입니다.
즉, 노란색으로 표시한 부분은 정답이고 9번째 줄 첫 번째에 있는 10개의 값들은 실제로 8이지만 0으로 예측된 값이라는 거죠.
8번째 줄 3번째에 있는 16 역시 7이지만 2로 예측한 값이 되겠죠.
이렇게 나타낸 행렬을 혼동행렬이라고 합니다.
주로 7을 2로 혼동하거나 5를 3으로 혼동한 건수가 많네요.
다음으로 마찬가지로 사이킷 런을 이용한 분류보고서인데요.
from sklearn.metrics import classification_report
print(classification_report(np.argmax(test_y, axis=1), np.argmax(pred, axis=1)))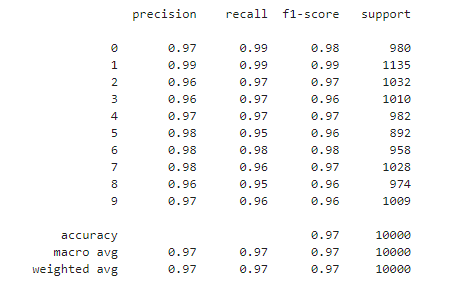
정확도가 전반적으로 97퍼센트 정도 내고 있지만 2,3,8이 입력되는 경우 약간 낮은 수치를 나타내네요.
일반적으로는 이 정확도를 중요하게 판단하지만 경우에 따라서는 정밀도나 재현율 등을 모델의 평가 지표로 사용하는 경우도 많다고 하니 참고하면 좋겠네요.
'프로그래밍 > 딥러닝' 카테고리의 다른 글
| 파이썬 딥러닝 텐서 플로우, 사이킷 런 등 설치 명령어 (0) | 2025.02.12 |
|---|---|
| 케라스에서 지원하는 MNIST 데이터셋 등 데이터셋 종류 (1) | 2024.03.22 |
| TensorFlow에서 사용되는 3가지 손실함수 (0) | 2024.03.20 |
| 딥러닝 활성화 함수 중 ReLU 쓰는 이유 (0) | 2024.03.19 |
| 아나콘다 가상환경 생성과 테스트 (0) | 2024.03.13 |

