
Notice
Recent Posts
Recent Comments
Link
말랑말랑제리스타일
[Pandas]판다스 인덱싱 - 인덱스 조정과 조회 조건 본문
우선 앞선 글을 읽지 않고 이 글을 이해하기 힘들 수 있으니 블로그 내에 판다스 인덱싱-데이터 조회 글을 먼저 읽어주시기 바랍니다. 링크는 아래에 첨부합니다.
https://jerry-style.tistory.com/47
[Pandas]판다스 인덱싱 - 데이터 조회
Pandas의 DataFrame과 Series에서 데이터를조회하는 작업은 거의 모든 분석에서 일어나는 작업으로 가장 먼저 해야될 작업 중 하나입니다. Native Accesors (접근자) 파이썬의 Native 객체는 데이터를 인덱싱
jerry-style.tistory.com
앞선 글에서 우리는 인덱스와 라벨을 이용해 데이터를 조회하는 방법을 알아보았습니다.
이번에는 인덱스를 조정하는 방법을 알아봅시다.
- 인덱스 조정
- Label-Based selection 즉, 라벨 기반 조회는 인덱스의 라벨을 기준으로 조회하기에 인덱스 지정 작업이 중요합니다. Pandas에서는 set_index() 함수를 이용해 특정 컬럼을 인덱스로 지정할 수 있습니다. 다음 예시는 latitude라는 컬럼을 인덱스로 적용한 예시입니다.
test_df.set_index("latitude")
- 위에 설명한 방법을 이용해서 보다 유용한 컬럼을 인덱스로 사용할 수 있습니다.
- Label-Based selection 즉, 라벨 기반 조회는 인덱스의 라벨을 기준으로 조회하기에 인덱스 지정 작업이 중요합니다. Pandas에서는 set_index() 함수를 이용해 특정 컬럼을 인덱스로 지정할 수 있습니다. 다음 예시는 latitude라는 컬럼을 인덱스로 적용한 예시입니다.
- 조회 조건 지정
- 지금까지는 DataFrame 자체 구조를 이용해서 조회해봤습니다. 그러나 더 유용한 결과를 가져오기 위해서는 조회 조건을 지정하는게 종종 필수적입니다. 예를들어 test_df DataFrame에서 어떤 row의 latitude가 34.10인지 확인해보겠습니다
test_df.latitude == 34.10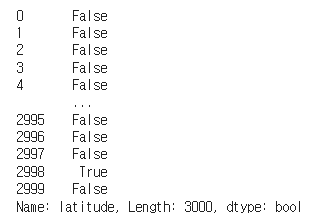
- 그렇다면 이번에는 34.10인 데이터만 조회하기 위해 앞선 인덱싱-데이터 조회 포스팅에서 썼던 Pandas의 loc 기능을 써보겠습니다.
test_df.loc[test_df.latitude == 34.10]
- 이와 같이 대괄호 내부에는 true, false인 값을 리턴하는 인자를 집어넣어줍니다. 결과 화면을 보면 latitude가 34.10인 값들만 조회된 것을 확인할 수 있죠.
- 조회 조건을 하나만 넣지 않고 두가지 이상 조합해서 사용하는 것도 가능합니다.
먼저 & 연산자를 사용해 두가지 조건을 모두 만족하는 결과를 추려보겠습니다.
test_df라는 DataFrame에서 loc를 이용하는 것까지 동일하고 소괄호로 감싸준 각각의 조건을 & 연산자로 연결해줍니다. 그럼 아래와같은 조회 결과가 나옵니다.test_df.loc[(test_df.latitude == 34.10) & (test_df.housing_median_age < 30.0)]
- 다음으로 | 연산자를 이용해 둘 중 어느 하나라도 만족하는 결과를 가져올 수도 있습니다.
test_df.loc[(test_df.latitude == 34.10) | (test_df.housing_median_age < 30.0)]
이런 구문을 사용하면 두개의 조회 조건 중 어느 하나라도 만족한다면 결과에 포함해서 조회하게 됩니다. - 추가로 Pandas에는 몇가지 조건 선택기가 있는데 주요한 두가지를 여기서 사용해보겠습니다. isin과 isnull이라는 기능입니다. 먼저 isin 사용 예를 보겠습니다.
test_df DataFrame에서 loc 기능을 이용하는 부분까지는 동일하고 조건에 isin을 사용해 housing_median_age가 대괄호([])로 감싸진 리스트에 포함되는 값들만 가져올 수 있습니다.test_df.loc[test_df.housing_median_age.isin(['10.0','40.0'])] - 다음으로 isnull과 notnull을 이용해 해당 값이 null인 데이터 또는 null이 아닌 데이터를 조회해볼 수 있습니다.
test_df.loc[test_df.housing_median_age.notnull()] test_df.loc[test_df.housing_median_age.isnull()]
- 지금까지는 DataFrame 자체 구조를 이용해서 조회해봤습니다. 그러나 더 유용한 결과를 가져오기 위해서는 조회 조건을 지정하는게 종종 필수적입니다. 예를들어 test_df DataFrame에서 어떤 row의 latitude가 34.10인지 확인해보겠습니다
- 데이터 할당
- 이번 장의 마지막인 데이터 할당입니다. isnull인 것과 같이 null인 값 또는 의미없는 값을 의미있는 값으로 할당해줄 수 있습니다. 이 Pandas 기능을 파이썬 코드로 표현하면 아래와 같습니다.
이렇게 할당해주면 total_rooms의 모든 값이 100.0으로 할당됩니다.test_df['total_rooms'] = 100.0
- 파이썬의 range 기능을 이용해 첫 row부터 전체 row 갯수(len(test_df))부터 마지막 row까지 -1씩 감소하면서 변하는 값을 할당해줄 수도 있습니다.
test_df['median_house_value'] = range(len(test_df),0,-1)
- 이번 장의 마지막인 데이터 할당입니다. isnull인 것과 같이 null인 값 또는 의미없는 값을 의미있는 값으로 할당해줄 수 있습니다. 이 Pandas 기능을 파이썬 코드로 표현하면 아래와 같습니다.
'프로그래밍 > 파이썬' 카테고리의 다른 글
| [Pandas]판다스 데이터 집계함수(Summary Function) (0) | 2022.01.19 |
|---|---|
| 구글 Colab에 외부 파일 올리기 (0) | 2022.01.18 |
| [Pandas]판다스 인덱싱 - 데이터 조회 (0) | 2022.01.17 |
| [Pandas]판다스 데이터 읽기(Colab 사용) (0) | 2022.01.16 |
| [Pandas] 판다스 시작하기 데이터 생성해보기 (0) | 2022.01.15 |
'프로그래밍/파이썬' Related Articles
more




Comments