
말랑말랑제리스타일
파이썬으로 테서렉트 OCR로 웹 이미지에서 글자 추출하기 본문
파이썬으로 테서렉트 OCR을 이용해 웹 이미지에서 글자를 추출하는 방법을 알아봤습니다. 환경은 구름 IDE에서 별도 설정하지 않고 파이썬으로 컨테이너를 만들고 커맨드로 테서렉트를 설치해 진행했습니다.
파이썬에서 테서렉트 사용하기 위한 환경 설정
먼저 구름 IDE에서 테서렉트를 사용하기 위해 리눅스 환경의 컨테이너에 테서렉트를 설치해 줍니다.
방법은 간단합니다. 컨테이너를 실행하면 하단에 터미널이 나오죠.
여기에 아래 명령어를 입력해 줍니다.
sudo apt install tesseract-ocr
이렇게 입력하면 설치 문구가 주르륵 나오면서 설치됩니다.
그리고 만약 이미지에서 한글 텍스트를 파싱 하고 싶다면 아래와 같은 명령어를 추가로 입력해 줍니다.
sudo apt-get install tesseract-ocr-script-hang tesseract-ocr-script-hang-vert자 이걸로 테서렉트 설치는 끝났고 파이썬 코드에서 사용할 예정이기 때문에 pip로 파이테서렉트도 설치해 줍니다.
sudo pip3 install pytesseract명령어는 이걸로 사용하면 되고요.

저 같은 경우 미리 설치를 해뒀기 때문에 업그레이드는 하지 않았네요.
자 이제 본격적으로 파이썬 코드를 다뤄봅시다.
구름 IDE에서 파이썬과 테서렉트를 이용해 웹 이미지의 텍스트 추출하기
먼저 구름 IDE에 세팅은 끝났고 index.py를 열어줍니다. 물론 파일 명은 상관없습니다.
그리고 아래의 소스를 추가해 필요한 라이브러리를 import 해줍니다.
from urllib import request
from PIL import Image
import pytesseract
from io import BytesIO간단히 파이썬 코드에 추가한 라이브러리 사용처를 설명하면 request와 io는 웹에서 이미지를 받아와서 바이트 단위로 바꿔줄 때 사용할 예정이고, Image는 해당 바이트화된 이미지를 저장할 때 변수를 사용할 겁니다.
그리고 가장 중요한 파이테서렉트는 웹이미지에서 텍스트를 추출할 때 사용하겠죠.
파이썬 코드로 웹에서 이미지를 불러와 변수에 바이너리 형태로 저장하기
자 이제 파이썬 코드를 이용해 웹에서 이미지를 불러와 Image 변수에 바이너리 형태로 저장해 봅시다.
image_url = "https://blog.kakaocdn.net/dn/E6ZAb/btsi2GpRiR9/qSxToYMKeneXQELeeZH390/img.png"
res = request.urlopen(image_url).read()
img = Image.open(BytesIO(res))먼저 image_url 변수에 텍스트를 추출하고자 하는 이미지의 웹 주소를 담아줍니다.
저는 제 블로그에 있는 이미지 중 하나의 웹주소를 입력했습니다.
다음으로 이미지 url에서 파일 내용을 받아와서 res 변수에 저장해 줍니다.
마지막으로 Image 클래스와 io 라이브러리를 이용해서 받아온 내용을 이미지 형태로 변환해 img라는 변수에 저장해 줍니다.
잘 받아졌는지 확인하기 위해서 아래 코드를 추가해서 사이즈를 확인해 봅니다.
print(img.size)429,168 사이즈를 잘 받아와 졌네요.
참고로 img.show 명령은 VS Code나 윈도우 에디터에서는 쉽게 사용할 수 있지만 구름 IDE에서는 별도 작업이 필요하니 지금은 넘어갑니다.
파이썬 코드로 웹에서 불러온 이미지에서 문자 추출하기
자 이제 본격적으로 이 이미지에서 텍스트를 추출해 봅시다.
파이썬 소스코드는 아래와 같습니다.
# 텍스트 추출
text = pytesseract.image_to_string(img)
# 텍스트 출력
print(text)파이테서렉트를 이용해 이미지가 담겨있는 img 변수에서 이미지를 추출해 주고 text 변수에 담아줍니다.
마지막으로 텍스트를 출력해 주면 소스가 끝납니다.
참고로 이미지 파일에서 한글 문자를 추출하고 싶다면 소스를 이렇게 바꿔줍니다.
text = pytesseract.image_to_string(img, lang = 'Hangul')이렇게 하면 한글 문자도 출력이 가능합니다.
마지막으로 전체 소스코드도 추가합니다.
from urllib import request
from PIL import Image
import pytesseract
from io import BytesIO
image_url = "https://blog.kakaocdn.net/dn/E6ZAb/btsi2GpRiR9/qSxToYMKeneXQELeeZH390/img.png"
res = request.urlopen(image_url).read()
img = Image.open(BytesIO(res))
res = request.urlopen(image_url).read()
img = Image.open(BytesIO(res))
# 텍스트 추출
text = pytesseract.image_to_string(img)
# 텍스트 출력
print(text)정확히 라이브러리를 가져오는 라인을 포함해 11줄로 웹에서 이미지를 가져와 텍스트를 추출하는 코드를 완성했습니다.
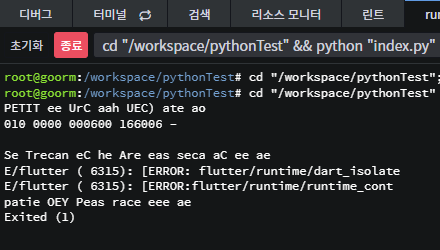
물론 테서렉트가 좀 느리기도 하고 한글의 경우 변환 능력이 떨어지긴 하지만 그래도 이 정도면 무료 라이브러리 치고는 상당히 괜찮은 성능인 것 같네요.
'프로그래밍 > 파이썬' 카테고리의 다른 글
| 파이썬으로 자동으로 누끼따서 배경 제거하기 (0) | 2023.06.13 |
|---|---|
| 구름 IDE에서 파이썬 PIL 이미지 미리보기 (0) | 2023.06.08 |
| How to change QLineEditText using QPushbutton in PyQt5 (0) | 2022.03.11 |
| 파이썬 PyQt5 로 윈폼 GUI 만들기 (0) | 2022.03.04 |
| 파이썬 lambda 함수의 뜻과 사용방법 (0) | 2022.02.16 |



